1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
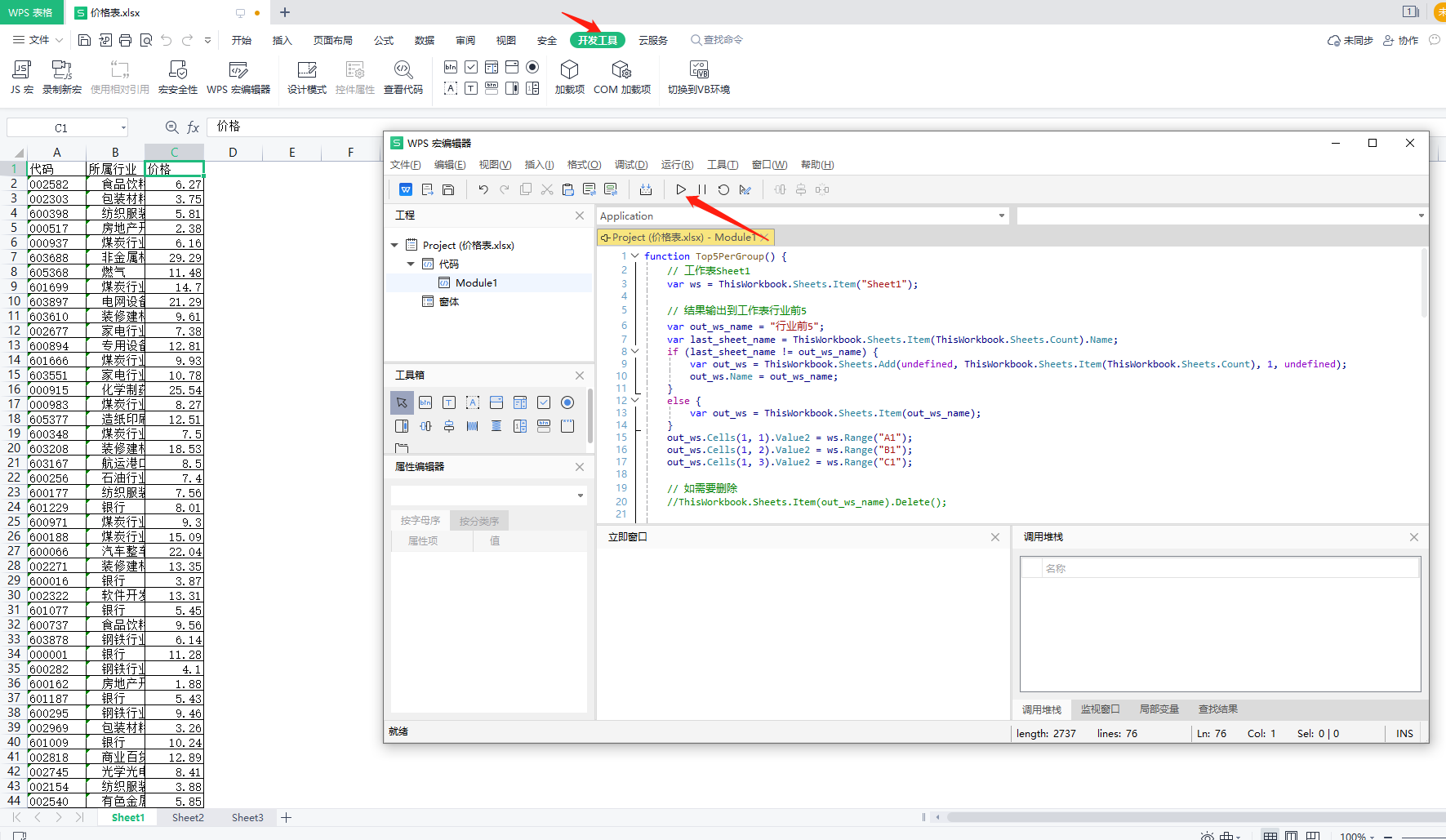
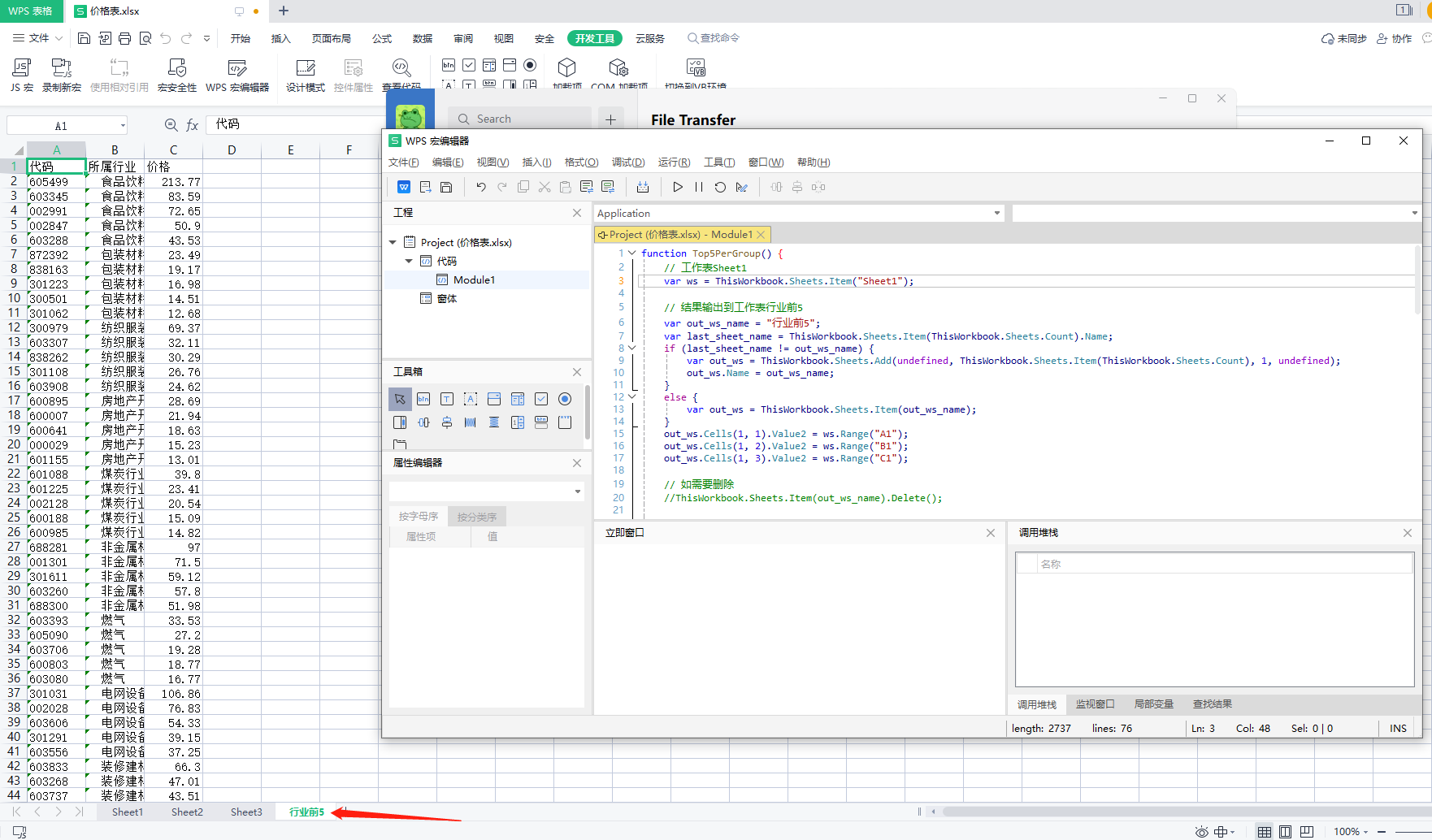
| function Top5PerGroup() {
// 工作表Sheet1
var ws = ThisWorkbook.Sheets.Item("Sheet1");
// 结果输出到工作表行业前5
var out_ws_name = "行业前5";
var last_sheet_name = ThisWorkbook.Sheets.Item(ThisWorkbook.Sheets.Count).Name;
if (last_sheet_name != out_ws_name) {
var out_ws = ThisWorkbook.Sheets.Add(undefined, ThisWorkbook.Sheets.Item(ThisWorkbook.Sheets.Count), 1, undefined);
out_ws.Name = out_ws_name;
}
else {
var out_ws = ThisWorkbook.Sheets.Item(out_ws_name);
}
out_ws.Cells(1, 1).Value2 = ws.Range("A1");
out_ws.Cells(1, 2).Value2 = ws.Range("B1");
out_ws.Cells(1, 3).Value2 = ws.Range("C1");
// 如需要删除
//ThisWorkbook.Sheets.Item(out_ws_name).Delete();
// 最后一行的行号
var last_row = ws.Cells(ws.Rows.Count, "A").End(xlUp).Row;
var code = ""; // 代码
var group = ""; // 行业
var price = 0; // 价格
var group_dict = {}; // 字典,键保存行业,值保存代码和价格,示例 {"行业A": [["代码1", 价格1], ["代码2", 价格2]]}
for (let i = 2; i <= last_row; i++) {
code = ws.Range("A" + i).Value().toString();
group = ws.Range("B" + i).Value();
price = ws.Range("C" + i).Value();
if (! (group in group_dict)) {
group_dict[group] = []; // 首次加入的行业,值置为数组
}
if (! isNaN(price)) { // 过滤掉非数字的价格
let codeAndPrice = [code, price]; // ["代码1", 价格1]
group_dict[group].push(codeAndPrice);
let value_arrary = group_dict[group]; // [["代码1", 价格1], ["代码2", 价格2]]
// 冒泡排序
for (let j = 0; j < value_arrary.length -1; j++) {
for (let i = 0; i < value_arrary.length - 1 - j; i++) {
if (value_arrary[i][1] < value_arrary[i + 1][1]) {
let temp = value_arrary[i + 1];
value_arrary[i + 1] = value_arrary[i];
value_arrary[i] = temp;
}
}
}
if (group_dict[group].length > 5) {
value_arrary.pop(); // 移除最后一个
}
}
}
//console.log(JSON.stringify(group_dict));
// 结果输出到out_ws
var groups = Object.keys(group_dict); // 所有行业
var row = 2;
for (let j = 0; j < groups.length; j++) {
if (group_dict[groups[j]].length === 0) {
continue;
}
for (let i = 0; i < group_dict[groups[j]].length; i++) {
out_ws.Cells(row + i, 1).Value2 = "'" + group_dict[groups[j]][i][0]; // 代码
out_ws.Cells(row + i, 2).Value2 = groups[j]; // 行业
out_ws.Cells(row + i, 3).Value2 = group_dict[groups[j]][i][1]; // 价格
}
row += group_dict[groups[j]].length;
}
}
|